The Gell-Mann Trap in AI-First Migrations: Why Augmentation Beats Replacement
Trusting AI on what you don't already know is the fastest way to ship wrong answers with confidence. Here's how to design an AI-first migration that lifts your team's work instead of quietly replacing their judgement.
By Jonathan Reeve · · industry
An AI-first migration that replaces human judgement is a confidence machine running with no brakes. It produces output that sounds right in domains your team doesn't know well, faster than anyone can verify it. The companies actually getting value out of AI right now haven't replaced their people. They've kept the experts and pointed AI at the parts of the job nobody wanted to do anyway.
The technical name for the trap is the Gell-Mann amnesia effect, and it's the failure mode underneath most of the AI horror stories you've been reading. It's worth understanding before you sign off on a migration plan.
Get this wrong and the cost isn't a few embarrassing emails. It's bad calls made on confident-sounding output, stacked on top of each other, in places where nobody on the team has the expertise to notice the call was bad in the first place.
What is the Gell-Mann amnesia effect?
The Gell-Mann amnesia effect is a phrase author Michael Crichton coined in a 2002 speech. It describes what happens when you read a newspaper article on a subject you actually know, find it riddled with errors, and then turn the page and read articles on subjects you don't know as if they're somehow more accurate. Crichton called the obvious cases "wet streets cause rain" stories, where the journalist gets cause and effect backwards because they don't understand the underlying domain.
His framing, in his own words:
"You read the article and see the journalist has absolutely no understanding of either the facts or the issues… you read with exasperation or amusement the multiple errors in a story, and then turn the page to national or international affairs, and read with renewed interest as if the rest of the newspaper was somehow more accurate about far-off Palestine than it was about the story you just read. You turn the page, and forget what you know."
Crichton wasn't really writing about journalism. He was describing how a brain handles confident, fluent text outside its zone of expertise. We grade fluency as accuracy. When the source has been right about everything we already knew, we extend that same trust to the parts we can't check, and the verification step we'd normally apply quietly stops happening.
Why AI is a Gell-Mann amplifier
LLMs are fluent by design. That's the whole point of them. The training objective rewards plausible next tokens, not correct ones, and the gap between those two things is where the Gell-Mann trap lives.
A model will write a contract clause that reads like a contract clause and a clinical guideline that reads like a clinical guideline. Whether either is correct is a separate question, and the answer depends entirely on whether someone who actually understands the domain is reading the output before it ships somewhere it can do damage.
If you migrate a workflow from "human expert produces output" to "AI produces output, nobody checks it," you've deleted the only person who could have caught the wet-streets-cause-rain errors. The output still reads fine, and now no one with the expertise to recognise an inverted cause is in the room.
The data: when AI helps work and when it hurts
This is where the field experiment gets interesting. In 2023, researchers at Harvard Business School, MIT, Wharton, and BCG ran a preregistered study (Dell'Acqua et al., HBS Working Paper 24-013) with 758 BCG consultants. Half got GPT-4. Half didn't. They called what they found the "jagged technological frontier": AI lifts performance for some tasks and quietly degrades it for others, even within the same job.
For tasks GPT-4 was good at, consultants using AI completed 12.2% more work, finished 25.1% faster, and produced higher quality output. For a complex managerial task that fell outside the model's frontier, the consultants using AI were 19% less likely to land on the correct answer than the consultants with no AI at all.
That second number is the Gell-Mann effect with a sample size attached. Skilled professionals, given a fluent model, did worse than their AI-free peers because the model produced confident output in a domain where it didn't belong, and the consultants didn't catch it.
The takeaway for a migration isn't "use AI" or "don't use AI." It's that the frontier is real, the frontier is jagged, and you have to know where it sits for the specific work in front of you before you decide what to automate.
The 66% problem: most teams aren't checking
If verification is what separates augmentation from amnesia, the global baseline looks rough. KPMG and the University of Melbourne's Trust, Attitudes and Use of Artificial Intelligence: A Global Study 2025 surveyed 48,340 people across 47 countries. The headline numbers:
- 66% of employees use AI tools at work without evaluating the accuracy of the responses.
- 56% report making mistakes in their work because of AI output.
- 57% admit hiding their AI use from employers and presenting AI work as their own.
- Only 47% have received any AI training.
Two-thirds of users skipping the check, half admitting AI-induced mistakes, and most of it happening in the parts of the org chart where the people responsible for quality can't see it. The technology is doing exactly what it's supposed to do. The system around the technology is missing.
What "augment, not replace" actually looks like in a migration
Augmentation isn't a softer marketing word for replacement. It's a structurally different setup. The expert stays in the chair. The AI takes the typing, the lookups, the formatting, the boring half of the job. What used to be a two-day month-end close becomes a four-hour review of what the model has already drafted.
A few patterns we lean on when we scope an AI-first migration.
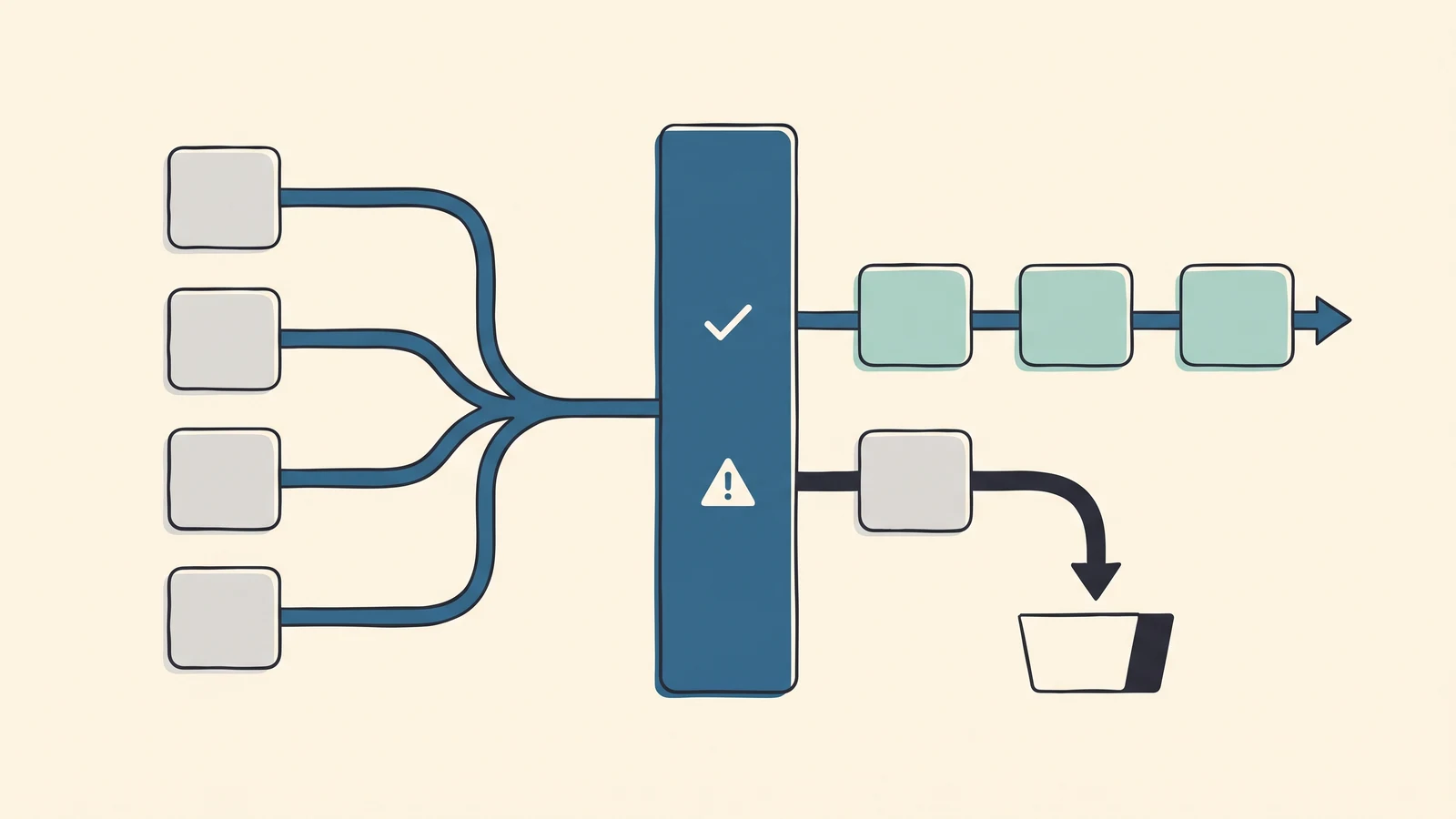
The first is matching the model to the cost of being wrong. We use LLMs where verification is cheap (drafts, summaries, classifications, extractions) because a human can scan a draft in seconds and either accept it or fix it. Where verification is expensive or impossible, we don't put the LLM in the position of final decision-maker. That's the corner of the workflow where the trap closes.
The second is a hard rule about output. Every AI output that leaves the system has to pass through some kind of verification step before it hits a customer, a regulator, or another system that depends on it. Either a human reads it, a deterministic rule checks it, or a second model with a different training objective gets to disagree with the first. Pick one per workflow. Picking none is what produces the headlines.
The third is routing by stakes rather than volume. Low-stakes ambiguous work can flow through AI plus a junior reviewer. Anything regulated, sensitive, or high-stakes belongs with an expert who has AI as a drafting tool, not a substitute. The expert keeps the call. The AI just makes the call cheaper to think through.
The fourth is making the model's confidence visible in the interface. The Gell-Mann trap thrives when every answer comes back in the same calm tone. Surfacing low log-prob outputs, flagging when a question lands outside the retrieved context, or just adding a "the model is uncertain about this row" badge in the UI is the cheapest intervention available, and almost nobody adds it.
The fifth is training. Half the global workforce hasn't been trained on AI tools, which means yours probably isn't either. The cheapest performance gain in any migration is teaching the team where the AI is good, where it falls apart, and how to tell the difference. None of the other patterns work without it.
What it looks like in practice
In every audit we've run, the same pattern shows up: a workflow that "sort of" works on day one and starts compounding errors by week three. The verification step that used to live in someone's head got automated out, and nobody noticed until a customer or a regulator did. It's almost never the model's fault. The model is doing exactly what fluent token prediction is supposed to do.
Take a finance team migrating their monthly close. The naive replacement migration generates the variance commentary with an LLM, drops it into the close package, and calls the workflow automated. The commentary will read fine. It will occasionally invert cause and effect on a non-obvious driver, and the only person who would have caught the error is the analyst whose job got "automated."
The augmenting version of the same migration is almost identical with one structural change. The LLM still drafts variance commentary from the trial balance and prior-period actuals. The analyst still owns the close. They review the numbers the model cited, the drivers it attributed them to, and any commentary on accounts the model has gotten wrong before. Their close time drops from two days to four hours, and their accuracy goes up, because the recovered hours go to the harder questions instead of typing.
Same model. Same task. The difference is whether the analyst is in the loop or out of it.
That kind of distinction is what a proper AI strategy audit exists to surface before any code gets written: which workflows can run on AI alone, which need an AI-plus-human gate, and which workflows have no business being touched by an LLM at all.
How to migrate without falling in
If you're scoping a migration right now, four questions will catch most of the Gell-Mann risk before it gets baked in.
Who currently catches errors in this workflow? If the honest answer is "the person we're removing," the verification layer is gone. It needs replacing on the way in, not after a customer notices something off.
Where does the AI output actually land? An internal draft a human will edit is a low bar. A regulated filing, a customer email, or a clinical recommendation is a much higher one. Match the bar to the consequence and write the controls accordingly.
What happens when the model is wrong? Silent acceptance is the failure mode you want to design out. Visible uncertainty and a clear escalation path are the controls that replace it.
And the one most teams forget: are the humans being trained alongside the migration, or is the training the line item nobody costed in? If 47% of the global workforce hasn't been trained, the safe assumption is that yours hasn't either. Budget for it before you ship the tool, not after the team starts hiding their use of it.
Done properly, an AI-first migration doesn't take jobs. It takes the parts of jobs that were never really the job, and it hands the team back the time. Output quality goes up, not because the AI got smarter, but because the humans got to spend their attention on the work that actually needed it.
The Gell-Mann problem isn't a reason to trust AI less. It's a reason to put the expert next to the output, where they can keep doing the part of the job that always required them anyway.
Planning an AI-first migration? Start with an audit, not an automation.
Book a free discovery call with Kobol. We'll map the Gell-Mann risk in your current workflows and show you which jobs are safe to automate, which need a human gate, and which ones we'd leave alone. Thirty minutes, no slides.
Book a Free Consultation